The Inner Alignment Problem

Neural networks may often behave differently from the intentions of the programmers. A useful distinction between the failure modes is between outer and inner misalignment.
Suppose you want to train an assistant to play a multiplayer strategy game for you. In the game, you build villages, train troops, create alliances or fight with other players. You observe that the most successful players usually have large armies, with which they can attack and destroy other players. Therefore, you train the assistant with the objective to maximize number of troops.
You soon realize that your barracks are crowded with the weakest unit which is not very suitable for battle. The assistant robustly fulfilled the goal — maximizing the number of troops — but you realized that this is not in fact what you intended.
Since the end goal of having many troops is to attack players from Aurora, an alliance you have always been at war with, you come up with an improved goal: Maximize number of destroyed villages of enemy players. Now, the assistant seems to be working flawlessly! It diligently gathers resources, builds balanced armies and attacks the enemy’s weakest points. The unthinkable happens: Aurora crumbles under the pressure and most of its members leave the game. However, soon you are facing a war with another alliance, Brotherhood. Eagerly, you await your assistant to wreak havoc upon the new enemies, but it does not launch any attacks, and now it’s the Brotherhood players who destroy your villages. You are dumbfounded: Why did it not destroy the enemy alliance?

After a short investigation, the reason is apparent: Instead of destroying enemy villages, the assistant only learned to destroy villages of Aurora players, which was the only enemy alliance it had seen during the training! The assistant seemed to be doing what you wanted, but it was actually optimizing something different.
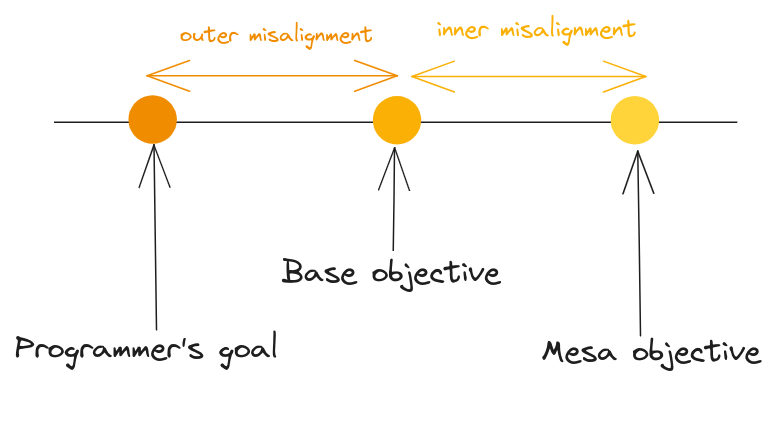
The first failure is an example of outer misalignment, while the second is an example of inner misalignment. These terms were introduced in Risks from Learned Optimization in Advanced Machine Learning Systems (Hubinger et al., 2019). In the rest of the post, I briefly summarize the alignment problem. The text in italics is used for emphasis, while "quoted text in italics" is used for quotes from the paper.
Mesa-optimization
The most important term in the paper is optimization: it is a search through space looking for some elements which score highly according to some objective function. The systems which perform optimization are optimizers.
Whether a system is an optimizer is a property of how the system works internally, not how the system behaves. The fact that a system performs some tasks really well does not mean it has to be an optimizer. An example from the paper is a bottle cap. The bottle cap does well the task for which it’s used, keeping the water inside the bottle. But it does not perform any optimization (a search). On the other hand, the creation of the bottle cap was an optimization process which found this particular gadget to work particularly well to keep the water inside.
But the system found by the optimization may be itself an optimizer. For example, consider evolution. We can approximate evolution as an optimizer that selects organisms based on genetic fitness. Most of the selected organisms (e.g. plants) are not optimizers and instead rely on heuristics selected by evolution. They do not have any goal of their own toward which they work. On the other hand, humans do have goals, and they actively try to achieve them — they are optimizers. However, the human objective functions, such as minimization of pain or sexual fulfilment, are not the same (though somehow related) as the evolution’s objective function of genetic fitness.
A similar situation may arise in learning algorithms. The learning algorithms (e.g. gradient descent) are optimizers in space of weights, with respect to some base objective (usually specified by programmers), and find an algorithm (learned algorithm) which performs the given task. The learned algorithm may itself be an optimizer. It may perform a search of its own, and its objective function may not be the same as the one used by the learning algorithm.
The first optimizer (e.g. gradient descent or evolution) is called base optimizer and optimizes base objective. The second optimizer (e.g. neural network or human brain) is called mesa-optimizer and optimizes mesa-objective.
The inner alignment problem
The base and mesa objectives may not be the same. While the base objective is specified by the programmers, mesa-objective is not. Since mesa-objective is found as a result of optimizing the base objective, they both will likely produce similar results on the training data. The elimination of the difference between the two objectives is called "the inner alignment problem”.
“The problem posed by misaligned mesa-optimizers is a kind of reward-result gap. Specifically, it is the gap between the base objective and the mesa-objective (which then causes a gap between the base objective and the behavioral objective). We will call the problem of eliminating the base-mesa objective gap the inner alignment problem, which we will contrast with the outer alignment problem of eliminating the gap between the base objective and the intended goal of the programmers.”
The goal is not to have exactly the same mesa objectives as the base objectives, but they should be robustly aligned, which means they “robustly agree across distributions”. This is in contrast to pseudo-aligned mesa objectives, which “agree with the base objective on past training data, but not robustly across possible future data (either in testing, deployment, or further training).”